15. Proxmox 설치
이 글에선 Proxmox 설치에 대해서 다룹니다.
준비물: Proxmox ISO 파일
Proxmox ISO 파일은 하기 링크에서 다운로드 받으실 수 있습니다.
https://www.proxmox.com/en/downloads/proxmox-virtual-environment/iso
1. ISO로 부팅 후 Install Proxmox VE (Graphical) 을 선택합니다.

보다 쉬운 설치를 위해 Graphical(GUI) 설치를 선택합니다.
2. EULA 에 동의합니다.

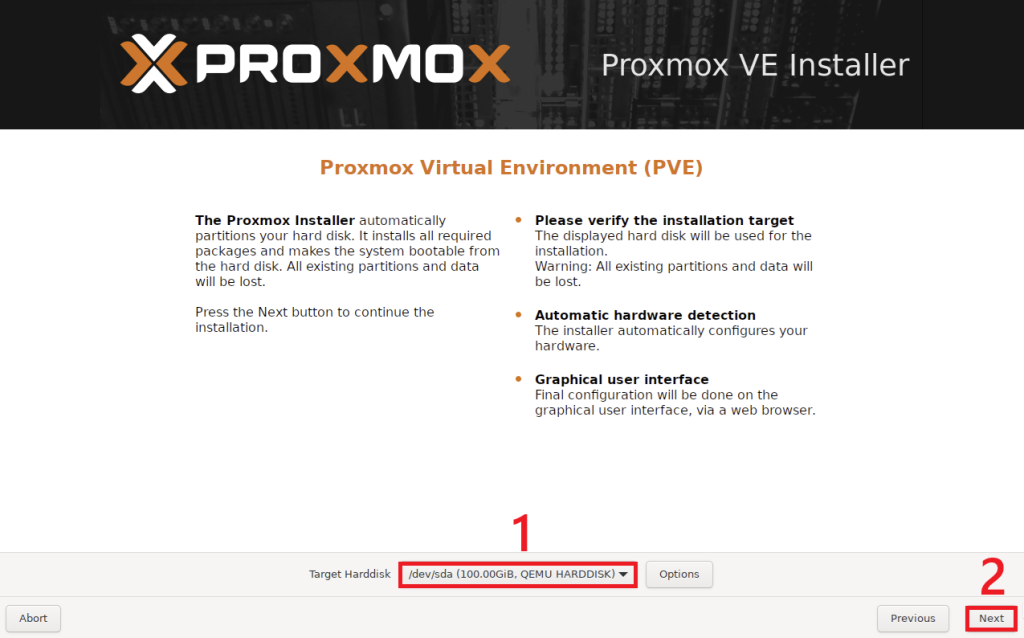
3. Proxmox OS가 설치될 Target Harddisk를 선택 후, Next를 누릅니다.
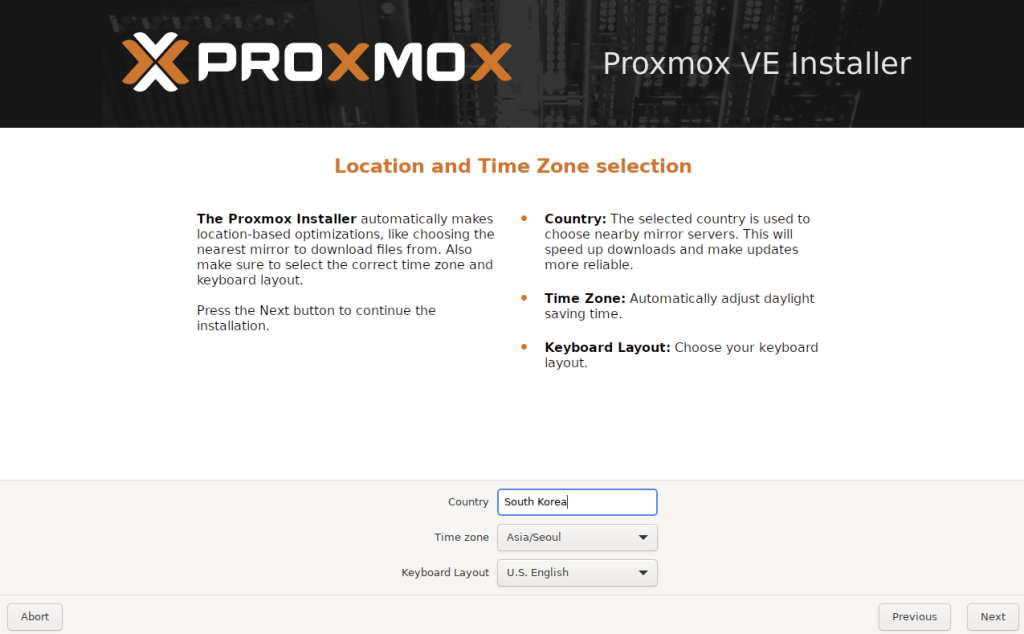
4. Country와 Time zone을 설정해줍니다.
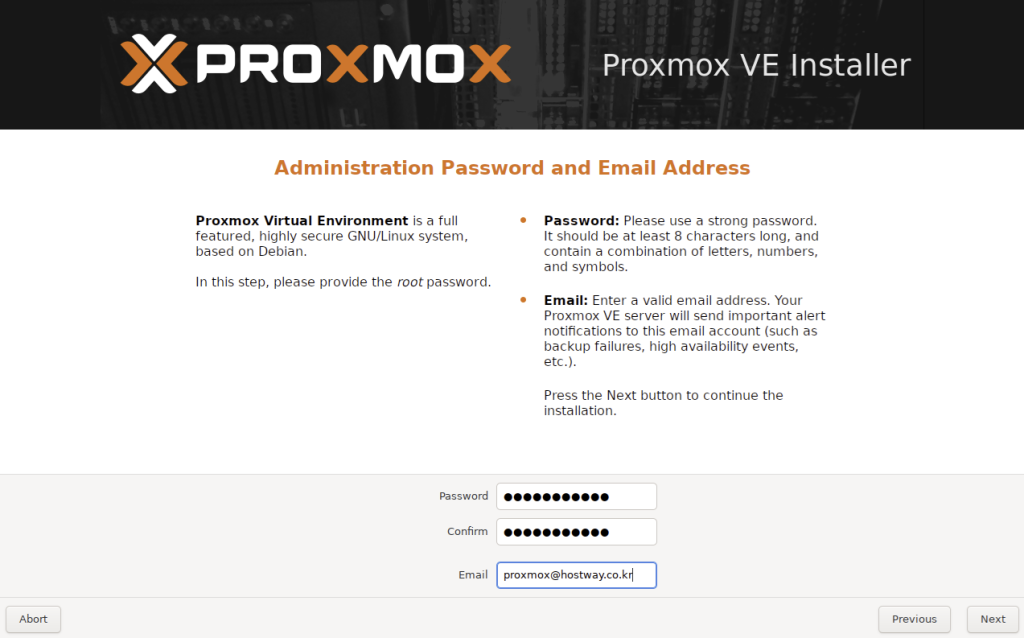
5. 패스워드와 Email을 작성합니다. Email에 설정된 주소로 Proxmox 서버에서 중요한 알림을 발송하게 됩니다.
6. NIC, Hostname, IP, DNS를 지정해줍니다.
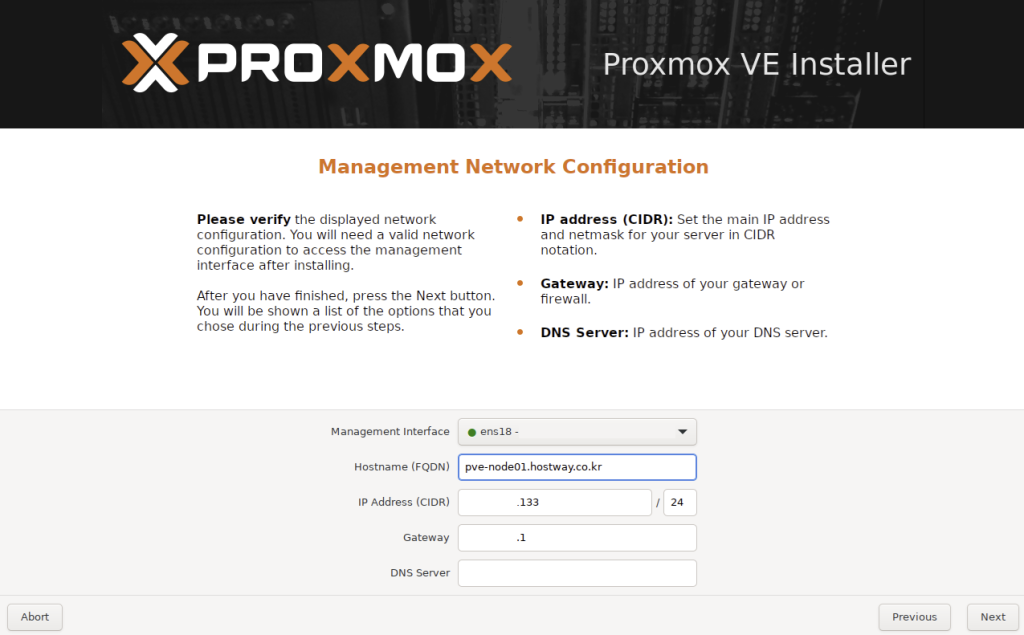
Management Interface: Proxmox의 웹 인터페이스 접속, API 통신, 클러스터 구성원 간의 통신 등에 사용되는 NIC을 지정해줍니다. 현재 체결되어있는 NIC은 좌측에 🟢표시됩니다.
Hostname (FQDN): Hostname + domain 주소로 작성합니다.
ex) hostname: pve-node01 / domain: hostway.co.kr 일 경우, pve-node01.hostway.co.kr
IP Address (CIDR): Proxmox Node에 부여할 IP를 Prefix, Gateway, DNS와 함께 작성합니다.
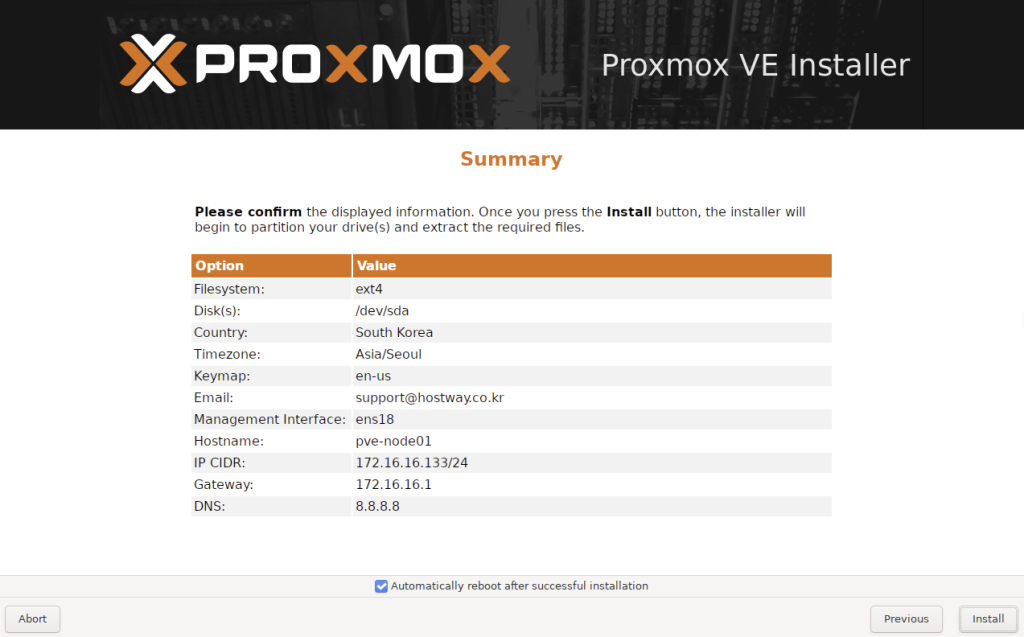
7. Summary에서 설정이 제대로 되었는지 확인 후, Install을 누르면 OS설치 후 재부팅이 됩니다.
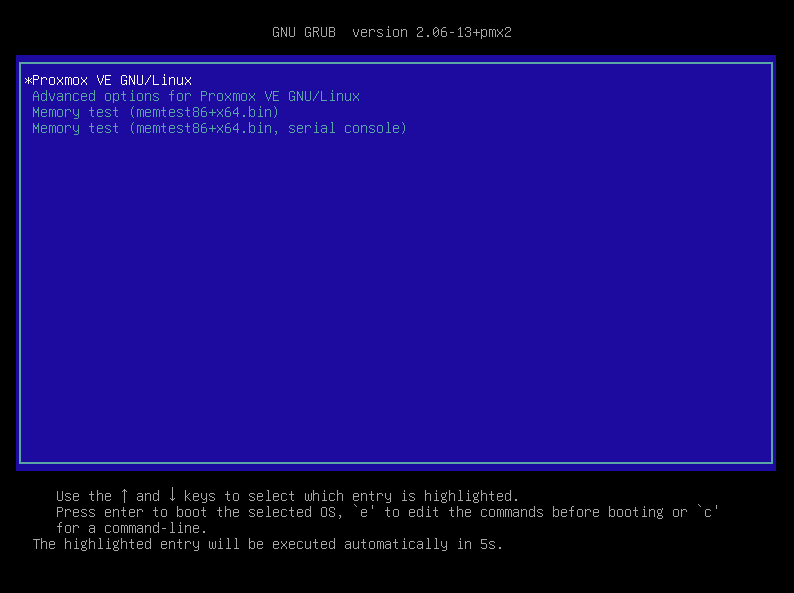
8. 재부팅 후, Proxmox VE GNU/Linux를 선택합니다(별도의 조작이 없을 경우, Default입니다.)
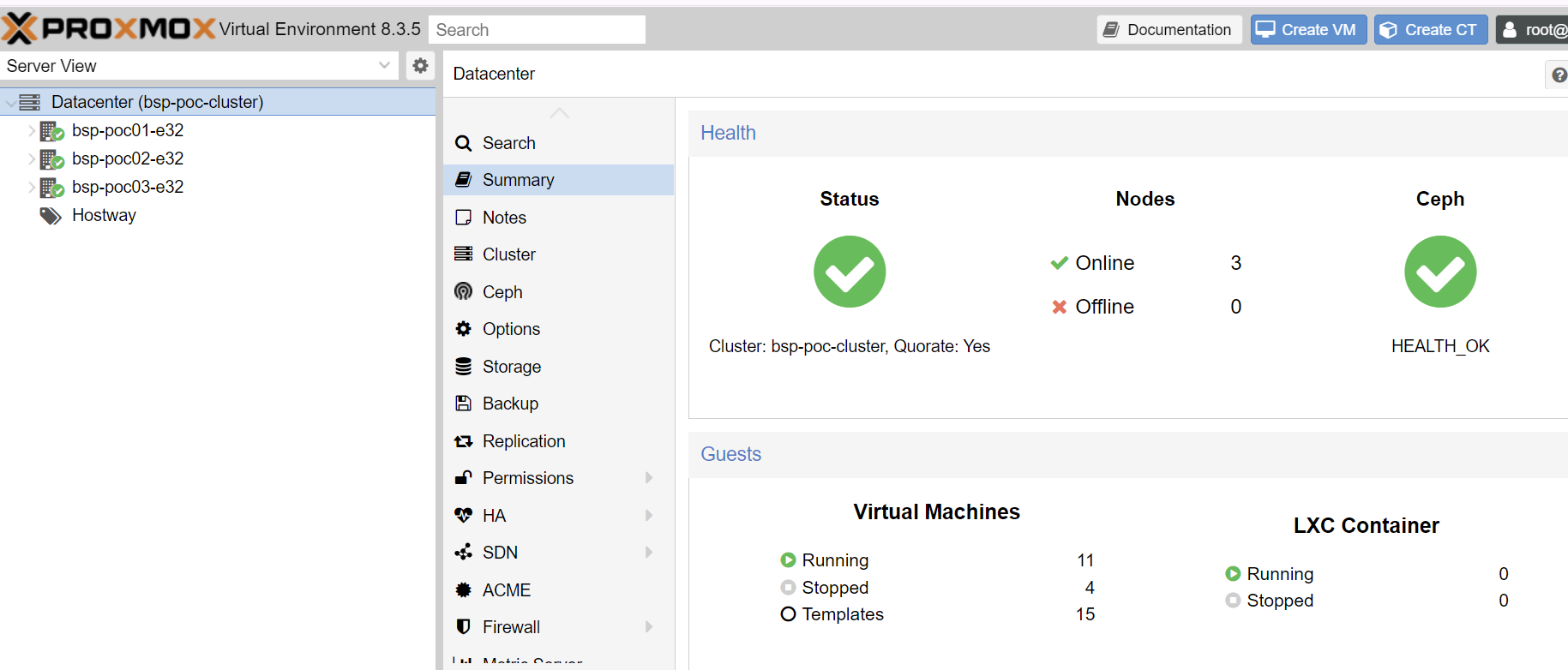
9. shell, ssh, 웹콘솔 정상 접속이 되는지 확인합니다.
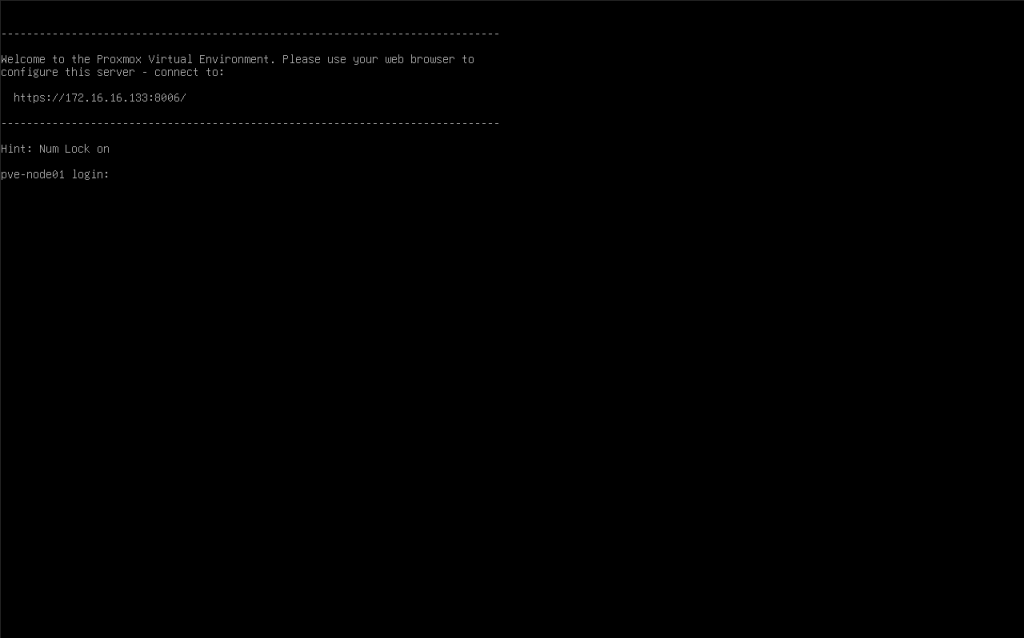
ssh: 22 port(default)
web console & API: 8006 port
상기 포트로 접근이 되지 않을 경우엔, 상단 방화벽 설정을 검토 합니다.(default open)